In this blog post I am going to show you the results of testing my Hadoop cluster (running on four Intel Galileo Gen 2 boards with 256MB RAM and a singel-core processor) and compare them to a Hadoop cluster running on four servers with 16GB RAM and a dual-core processor. I will run two different kinds of Tests. The first test is a simple word count. This is part of the Apache Hadoop distribution, so it should already be available in your cluster. For the second test I´m running the Mahout recommendation engine on different sets of movie ratings. The result is a movie recommendation for each User.
- Prerequisites
- WordCount
- Mahout recommendation engine
1. Prerequisites
First of all you need access to a running hadoop cluster. If you want to set up your own cluster, my earlier post might help you:
https://uc-lab.in.htwg-konstanz.de/blogging/blogger/listings/mario-miosga.html
For the first test, that´s everything you need till this moment.
For my second test you need to download Mahout and extract it on your Master Node:
http://www.apache.org/dyn/closer.cgi/mahout/
My cluster is running with Hadoop 2.6.0 and I installed Mahout 0.10.0.
2. WordCount
As I said, with a working hadoop cluster we have almost everything we need to run the test. I say almost, because of course we need some text files to run a word count. I recommend downloading a Wikipedia database dump. Of course you can use any other text file as well.
To run the test the first thing you have to do is to create a directory on HSDF (Hadoop Distributed File System), in which you want to store your files on the cluster. To do that, you execute this command on your Master Node:
hdfs dfs -mkdir /Dir/On/Hdfs/
Now, that we have an empty directory on our cluster, we copy our files on it. The "-copyFromLocal" command is executed recursiv, so that you can enter a hole folder with several text files.
hdfs dfs -copyFromLocal /Local/Path/To/Your/Text/Files /Dir/On/Hdfs
Finally, we can run our test! As I said before, Hadoop itself as some tool you can use to test your cluster. These Tools are Part of the Apache Hadoop distribution, so they are located in your Hadoop install directory.
To run the test, execute the following command:
hadoop jar /HadoopDir/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /Dir/On/Hdfs /Output/Dir/On/Hdfs
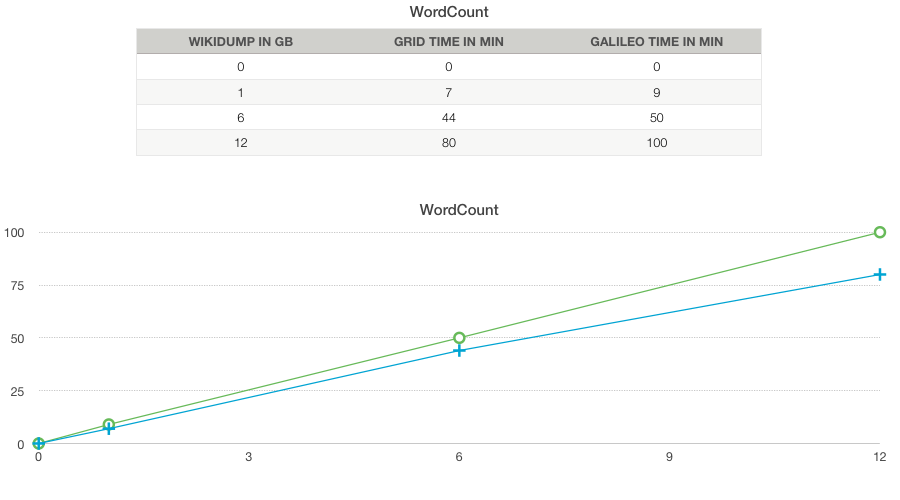
I run this Test with three different sizes (1GB, 6GB, 12GB).
(click to enlarge)
3. Mahout recommendation engine
Of course, for this test we need different files as for the word count. It is necessary, that the files contain a user-ID, item-ID and a rating. The user-ID and item-ID have to be integer values, the rating should be also an interger or a double value. The three values are seperated with a tab and each rating has to be in a new line.
So that is the Format that we need:
[user id] [item id] [rating]
[user id] [item id] [rating]
.
.
.
The GroupLens Movie DataSet provides the rating of movies in this format. As you can see, the largest data set contains 20 million ratings an has a size of 132MB. I wanted to test my cluster with larger files. That´s why I wrote a small java application to generate my own data sets.
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Random;
public class Main {
public static void main(String[] args) throws IOException {
try {
writeFile1();
writeFile2();
writeFile3();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void writeFile1() throws IOException {
File fout = new File("200MB.data");
FileOutputStream fos = new FileOutputStream(fout);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(fos));
for (int userID = 0; userID 300000; userID++) {
for (int y = 0; y 50; y++) {
int rMovieID = new Random().nxtInt(20000);
int rUserRating = new Random().nextInt(5);
bw.write(userID + "t" + rMovieID + "t" + rUserRating);
bw.newLine();
}
}
bw.close();
}
public static void writeFile2() throws IOException {
File fout = new File("600MB.data");
FileOutputStream fos = new FileOutputStream(fout);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(fos));
for (int userID = 0; userID 900000; userID++) {
for (int y = 0; y 50; y++) {
int rMovieID = new Random().nxtInt(20000);
int rUserRating = new Random().nextnt(5);
bw.write(userID + "t" + rMovieID + "t" + rUserRating);
bw.newLine();
}
}
bw.close();
}
public static void writeFile3() throws IOException {
File fout = new File("1GB.data");
FileOutputStream fos = new FileOutputStream(fout);
BufferedWriter bw = new BufferedWriter(new OutputStreaWriter(fos));
for (int userID = 0; userID < 1500000; userID++) {
for (int y = 0; y 50; y++) {
int rMovieID = new Random().nextInt(20000);
int rUserRating = new Random().nextInt(5);
bw.write(userID + "t" + rMovieID + "t" + rUserRating);
bw.newLine();
}
}
bw.close();
}
}
This program generates three files (~200MB, ~600MB and ~1GB) where each user gives 50 movie ratings within a list of 20.000 movies. The number of users depends on the file size.
Mahout will execute several Hadoop Map-Reduce jobs. The result of this test is a recommendation of 10 movies for each user based on their own ratings.
If you have your files, you have to put those files on the hdfs the same way, as in the word count example:
Make the directory on the hdfs:
hdfs dfs -mkdir /Dir/On/Hdfs/
And copy the files from your local directory to the hdfs directory:
hdfs dfs -copyFromLocal /Local/Path/To/Your/Text/Files /Dir/On/Hdfs
Now lets run the mahout job:
hadoop jar /MahoutDir/mahout-examples-0.10.0-job.jar org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -s SIMILARITY_COOCCURRENCE --input /Dir/On/Hdfs --output /Output/Dir/On/Hdfs
With the argument "-s SIMILARITY_COOCURRENCE", we tell the recommender which item similary formula to use. With SIMILARITY COOCURRENCE, two items(movies) are very similar if they often appear together in users' rating. So to find the movies to recommend to a user, we need to find the 10 movies most similar to the movies the user has rated.
The output of the Test looks like this:
0 [18129:5.0,13737:5.0,8951:5.0,7213:5.0,16772:5.0,7642:5.0,4069:5.0,411:5.0,2791:5.0,16759:5.0]
1 [2059:5.0,10184:5.0,17590:5.0,2871:5.0,870:5.0,19185:5.0,1281:5.0,6392:5.0,1117:5.0,7139:5.0]
2 [11044:5.0,18414:5.0,14435:5.0,3349:5.0,17946:5.0,16225:5.0,14865:5.0,15280:5.0,10023:5.0,6906:5.0]
3 [14065:5.0,5897:5.0,4739:5.0,5667:5.0,3598:5.0,6008:5.0,4054:5.0,9527:5.0,2844:5.0,19040:5.0]
4 [623:5.0,381:5.0,12273:5.0,14361:5.0,13688:5.0,2695:5.0,16203:5.0,6254:5.0,18800:5.0,11605:4.6666665]
5 [5942:5.0,17290:5.0,2350:5.0,14588:5.0,12910:5.0,15978:5.0,5824:5.0,15934:5.0,9882:5.0,2154:5.0]
6 [19701:5.0,14598:5.0,11787:5.0,12366:5.0,16515:5.0,4657:5.0,1440:5.0,15894:5.0,7540:5.0,10954:5.0]
7 [2299:5.0,9519:5.0,989:5.0,16658:5.0,3011:5.0,13744:5.0,6464:5.0,750:5.0,1356:5.0,14518:5.0]
8 [2965:5.0,360:5.0,1719:5.0,18470:5.0,1475:5.0,6528:5.0,516:5.0,8982:5.0,10998:5.0,2161:5.0]
9 [10924:5.0,4717:5.0,6913:5.0,5931:5.0,18297:5.0,1574:5.0,6579:5.0,13359:5.0,4983:5.0,5285:5.0]
10 [3263:5.0,2423:5.0,17065:5.0,4752:5.0,8871:5.0,12535:5.0,17389:5.0,3579:5.0,19333:5.0,6204:5.0]
11 [19639:5.0,14863:5.0,18538:5.0,11561:5.0,11348:5.0,15314:5.0,1293:5.0,5260:5.0,7448:5.0,15790:5.0]
12 [412:5.0,12430:5.0,7073:5.0,19512:5.0,1864:5.0,19451:5.0,4155:5.0,2562:5.0,10372:5.0,11274:5.0]
13 [5741:5.0,4280:5.0,16453:5.0,14721:5.0,7230:5.0,360:5.0,1183:5.0,11208:5.0,4705:5.0,1845:5.0]
14 [6457:5.0,16468:5.0,6075:5.0,3295:5.0,4177:5.0,6267:5.0,3637:5.0,4620:5.0,4344:5.0,1189:5.0]
15 [10199:5.0,180:5.0,7722:5.0,7684:5.0,3281:5.0,18349:5.0,19715:5.0,10212:5.0,13544:5.0,13517:5.0]
16 [9406:5.0,19185:5.0,15019:5.0,4708:5.0,14244:5.0,9778:5.0,5444:5.0,1925:5.0,5568:5.0,15664:5.0]
17 [17349:5.0,2665:5.0,2565:5.0,18053:5.0,2489:5.0,6308:5.0,2470:5.0,8941:5.0,2959:5.0,2457:5.0]
18 [14841:5.0,7721:5.0,1969:5.0,11501:5.0,10028:5.0,6653:5.0,504:5.0,4873:5.0,12254:5.0,1000:5.0]
19 [8657:5.0,3315:5.0,18896:5.0,10786:5.0,10334:5.0,5670:5.0,4591:5.0,2946:5.0,2049:5.0,4016:5.0]
20 [10390:5.0,13986:5.0,16931:5.0,8973:5.0,3959:5.0,4917:5.0,8398:5.0,5220:5.0,13010:5.0,5929:5.0]
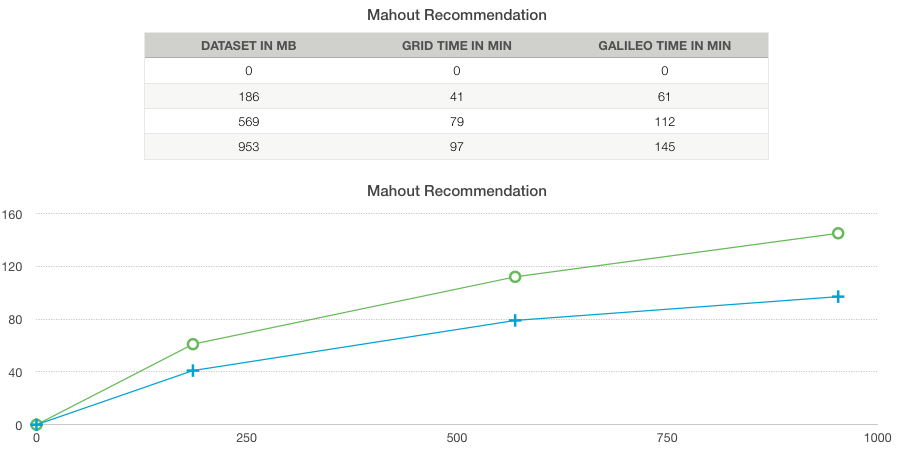
Here you can see the 10 recommended movies for each user.
(click to enlarge)
A big issue that I was facing during the tests is the small amount of RAM on the Galileo boards.
As a result, this error occurred very often during the tests:
java.lang.Exception: java.lang.OutOfMemoryError: Java heap space
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
Caused by: java.lang.OutOfMemoryError: Java heap space
In a Hadoop cluster, it is important to balance the usage of memory (RAM), processors (CPU cores) and disks so that processing is not constrained by any one of these resources. As a general recommendation, allowing for two Containers per disk and per core gives the best balance for cluster utilization.
When determining the appropriate MapReduce memory configurations for a cluster node, start with the available hardware resources. Specifically, note the following values on each node:
RAM (Amount of memory)
CORES (Number of CPU cores)
DISKS (Number of disks)
A detailed tutorial on how to configure the resource usage can be found at this article:
Determine HDP Memory Configuration Settings